
We thought collecting data was the hard part
Before starting Ronja, we (Anton and Adam) spent years at Northvolt building data infrastructure at scale. Systems that ingested petabytes per year. Sensor data from battery production lines, supply chain signals, quality metrics from every cell that rolled off the line. The objective felt clear: collect everything, because with all that data, we'd make better decisions. We'd outcompete.
And the collection part worked. We built the pipelines. The data flowed. But somewhere between "we have the data" and "we're making better decisions," something broke. Not the infrastructure. The assumption.
Using data is where everything breaks
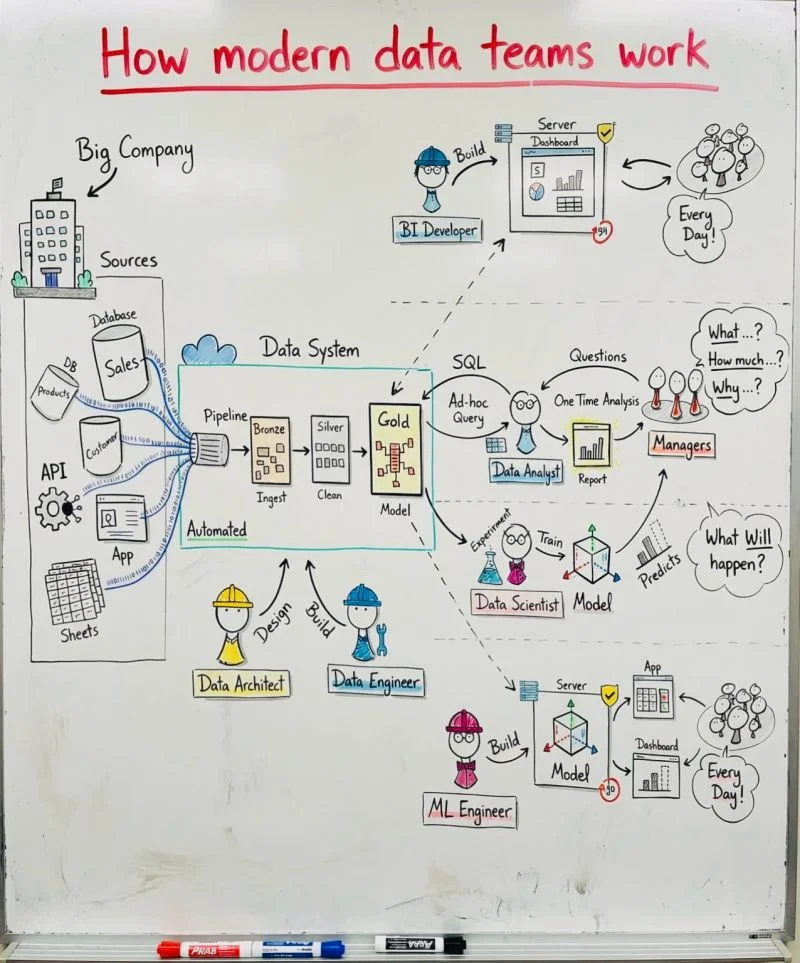
Here's what we kept seeing, at every company we've spoken to: the data is there, but the people who need it can't reach it. A head of sales wants to know which accounts are at risk of churning. A CFO wants to understand gross margin by product line. A plant manager wants to correlate downtime with a specific supplier. These aren't complicated questions. But getting answers is.
Because the data needs to be ingested from source systems, cleaned, modelled into something trustworthy, and then served through a tool that someone can actually use. Each of those steps requires a different specialist. The business user goes to an analyst, who involves a data scientist, who needs a data engineer, who might need to loop in the platform team. A simple question becomes a ticket, then a backlog item, then a two-week wait. And when the answer finally arrives, it raises three new questions. Back to the queue.
The reality of getting from question to answer in most companies.
The data is there. But it's hidden behind layers of complexity, out of reach for the people who actually understand the business well enough to interpret it. The stack isn't shaped around how decisions get made. It's shaped around how specialists like to work.
The modern data stack doesn't feel very modern
The industry calls it the "modern data stack." Fivetran for ingestion. Snowflake or BigQuery for storage. dbt for transformation. Power BI or Looker for visualization. Four separate tools, four vendors, four contracts. And a data team to glue it all together. For a mid-sized company, the total cost runs between $270k and $950k per year, most of it in people. The backlog never shrinks. The people who understand the business best are the furthest from the data.
This entire architecture was built on a single assumption: humans are the glue between systems. Every layer needs its own specialist and its own tool because that's how the work got divided when humans had to write every query, every pipeline, every dashboard by hand. That made sense in 2015. It doesn't anymore. What we call "modern" is really a decade-old answer to an even older problem, carried forward by convention and tool fragmentation.
This is an anti-pattern for AI
The instinct right now is to bolt AI onto the presentation layer. A copilot in your BI tool. An autocomplete in your SQL editor. A chatbot on top of your warehouse. But none of these can build the governed data layer that connects the question to the answer. They can suggest a chart. They can autocomplete a query. But they can never build the pipeline, model, or data layer that doesn't exist yet. That requires a new layer, not a new coat of paint.
You can't get AI-native outcomes from a human-native architecture.
The challenge is not the tools themselves. It is the gap between them and the people who need answers. AI needs end-to-end context: what data exists, where it comes from, how it relates, what the business calls it. Filling that gap is what the last mile is for.
The achilles heel of AI: numbers and data
There's a fundamental problem with asking AI to work directly with numbers: numbers can't be next-token predicted. Language models are built to predict the next word in a sequence. That works brilliantly for text and code. But when you ask an AI to compute, aggregate, or reason about numerical data, it approximates. And approximation on numbers means hallucination. A revenue figure that's close but wrong. A trend that looks plausible but isn't grounded in the data. This is why general-purpose AI assistants can feel magical for simple questions, and produce answers you can't trust when the stakes are real.
But AI is exceptionally good at writing code. Code that connects to databases, transforms data, runs calculations, and returns exact results. The output isn't a guess. It's the result of executed logic against real data.
AI can't predict numbers. But it can write the code that calculates them.
The catch: this only works under three conditions. First, the code must actually execute against real data, not simulate an answer. Second, the pipelines must persist, not disappear after one conversation. And third, the context must be carefully managed: what data exists, how it relates, what the business calls things, which calculations matter.
This is the core insight behind Ronja. We let AI explore and experiment with your data, but through code. Every question triggers real, executable pipelines. Every answer is backed by auditable logic. Deterministic. Reproducible. Traceable to source.
So we built something different
If you rebuilt the data stack from scratch in the age of AI, you wouldn't add another tool to the pile. You'd add a governed last-mile layer where agents handle routine data requests, every answer traces to source, and the data team finally gets to focus on the hard problems. One platform where a CFO can ask a question and get a trustworthy, traceable answer without knowing what SQL is.
That's what we're building with Ronja. Not another tool bolted on top. A governed execution layer that sits between your existing data infrastructure and the people who need answers. Everything is deterministic and traceable to source. No hallucinations. Every model the agents build becomes part of your data layer. Tested, documented, reusable. The platform gets smarter the more your team uses it.
Ronja Technologies was founded in 2024 in Stockholm, building a governed, last-mile execution layer for self-serve analytics at scale.
Others query what exists. Ronja builds what's needed.

